结合pandas学习《极简统计学》。第一章《用频数分布表和直方图刻画数据的特征》练习。
理论
根据原始数据什么也搞不明白,所以使用统计。
“统计”的手法,就是从原始数据,也就是“原始的现实”中,抽取出分布的特征和特点的方法。
统计学使用的方法叫“压缩”,是指“将作为数据列举的大量数字,以一定的基准进行整理,只抽取有意义的信息”。大致有以下两种手法:
- 以图化捕捉其特征。
- 以一个数字来代表特征。此数字叫做“统计量”。
做频数分布图,首先需要做频数分布表,步骤如下:
- 找到数据中的最大值和最小值;
- 分组:按最大值、最小值划分范围;
- 决定“组值”:一般选择中间的数值;
- 数出各组中的数据数——“频数”;
- 计算“相对频数”,即各组的频数占全体的比例,相对频数相加等于1;
- 计算“累计频数”,即频数合计,累计频数最终与全部数据数一致。
做直方图的步骤:
- 在横轴上以等间距放置组值;
- 在各组值上做柱形,柱的高度参考其组值所属分组的频数。
练习
题目
女大学生体重数据如下,请做频数分布表和直方图:
48, 54, 47, 50, 53, 43, 45, 43, 44, 47,
58, 46, 46, 63, 49, 50, 48, 43, 46, 45,
50, 53, 51, 58, 52, 53, 47, 49, 45, 42,
51, 49, 58, 54, 45, 53, 50, 69, 44, 50,
58, 64, 40, 57, 51, 69, 58, 47, 62, 47,
40, 60, 48, 47, 53, 47, 52, 61, 55, 55,
48, 48, 46, 52, 45, 38, 62, 47, 55, 50,
46, 47, 55, 48, 50, 50, 54, 55, 48, 50
频数分布
1 | import numpy as np |
计算频数:1
2counts = pd.value_counts(cuts)
dict(counts)
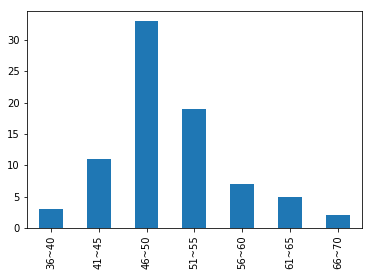
{‘36~40’: 3,
‘41~45’: 11,
‘46~50’: 33,
‘51~55’: 19,
‘56~60’: 7,
‘61~65’: 5,
‘66~70’: 2}
直方图
1 | cuts.value_counts().plot(kind='bar') |